一次线上OOM问题排查
一次线上OOM问题排查
生产环境的JVM进程经常被运维报告有OOM的情况,运维的描述是,内存一直在缓慢增长,1-2天就会出现OOM的情况。因为已经严重影响到客户的使用,所以采取由运维定时监控,与客户交流,开发负责排查问题的策略。
Step1:测试环境复现问题
由于开发是没权限进入生产环境的,要高效率解决问题,必须能在测试环境复现。查看生产环境的日志,确认容器出发OOM的接口,然后使用Jmeter在测试环境压测该接口,发生OOM的情况,问题能够复现。
Step2: 在测试环境复现
在测试环境建一个和生产环境规格一样的容器,使用Jmeter压测,确认问题能复现。
Step3: 初步确认问题原因
查看Java应用日志,没有OOM信息,使用dmesg查看系统日志,确认是因为OOM而被操作系统杀掉。
kernel: [1799319.246494] Out of memory: Kill process 28536 (java) score 673 or sacrifice childSep
kernel: [1799319.246506] Killed process 28536 (java) total-vm:1271568kB, anon-rss:426528kB, file-rss:0kBStep4: 在压测过程中观察指标
top命令观察内存占用情况arthas观察JVM的内存情况jcmd观察JVM的内存情况
容器内存为8GB,堆内存设置为5.6GB开始第一次观察。
第一次观察
压测前和压测过程中已经在内存快爆之前使用jcmd观察内存情况,发现total的committed和reserved大小只有小幅度的上升,而top里观察到的RES值一直在上升,直至内存爆掉。
而total committed的值为7.2GB,非常接近容器的8GB,未压测前虽然committed 的total差不多为7G,但是这些内存未被实际使用,所以没有被映射到物理内存里,所以开始时RES值比committed低很多,随着压测进行,越来越多内存被交换到物理内存里,最后容器内存超过8G被killed。
由于堆外内存使用量大,堆内存不能配置为容器内存的70%,改为4GB,容器内存的50%值再压力测试。
第二次观察
堆内存改为4GB后,进行一个小时的压测,容器不再被killed,JVM也未OOM。但此时还有一个问题,top观察到的物理内存RES占用比jcmd里的committed高很多,也就是说,jcmd追踪不到的堆外内存占用多,需要排查是什么占用了这部分内存。
使用pmap观察进程内存的变化,发现压测前和压测后比对,pmap里多了大约100个15M左右的anon内存块。
使用smaps获取可疑的15M内存块的起始地址和结束地址,之后使用gdbdump出内存块。
启动gdb
gdb -p <pid>
dump指定内存地址到指定的目录下,参数的地址需要在smaps拿到地址前加上0x。
dump memory /tmp/0x7fb9b0000000-0x7fb9b3ffe000.dump 0x7fb9b0000000 0x7fb9b3ffe000
显示长度超过10字符的字符串。或者把内存块下载到本地,使用vscode之类的文本编辑器打开分析,或者使用二进制编辑器分析二进制。也可以使用string查看字符串内容。
strings -10 /tmp/0x7fb9b0000000-0x7fb9b3ffe000.dump
发现内存块中有大量的jar包里的MANIFEST.MF文件的字符串,猜测是代码里有加载jar包到堆外内存里。
第三次观察
在压测过程中观察JVM的线程栈。
注意到压测大部分线程的栈都在以下RUNNABLE中,
at java.util.zip.Inflater.inflateBytes(Native Method)
at java.util.zip.Inflater.inflate(Inflater.java:259)
- locked <0x00000007720e8bf0> (a java.util.zip.ZStreamRef)
at java.util.zip.InflaterInputStream.read(InflaterInputStream.java:152)
at sun.misc.IOUtils.readFully(IOUtils.java:163)
at java.util.jar.JarFile.getBytes(JarFile.java:452)
at java.util.jar.JarFile.getManifestFromReference(JarFile.java:196)
at java.util.jar.JarFile.getManifest(JarFile.java:184)
at com.sun.tools.javac.file.FSInfo.getJarClassPath(FSInfo.java:69)
at com.sun.tools.javac.file.Locations$Path.addJarClassPath(Locations.java:305)
at com.sun.tools.javac.file.Locations$Path.addFile(Locations.java:296)
at com.sun.tools.javac.file.Locations$Path.addFiles(Locations.java:236)
at com.sun.tools.javac.file.Locations$Path.addFiles(Locations.java:242)
at com.sun.tools.javac.file.Locations$SimpleLocationHandler.setLocation(Locations.java:439)
at com.sun.tools.javac.file.Locations.setLocation(Locations.java:697)
at com.sun.tools.javac.file.JavacFileManager.setLocation(JavacFileManager.java:798)
at com.xxx.xxx.JavaCompileService.compile(JavaCompileService.java:86)业务代码这个接口会使用JavaCompiler动态编译代码,又由于at java.util.zip.Inflater.inflateBytes(Native Method)这里是使用堆外内存加载zip文件,猜测就是这里代码把jar包加在到堆外内存中。
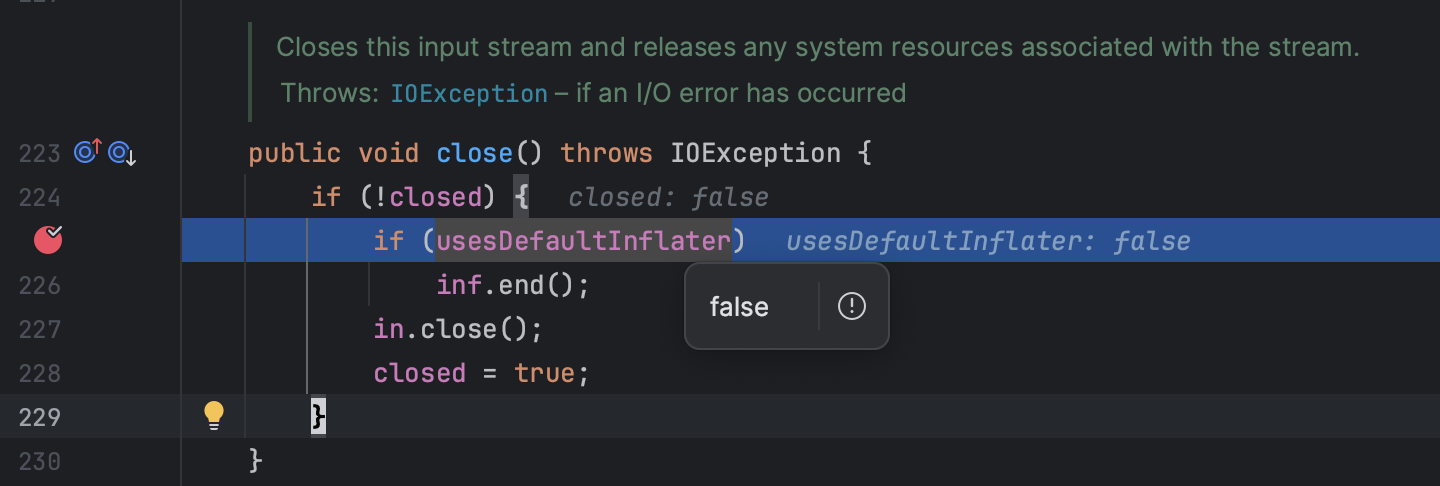
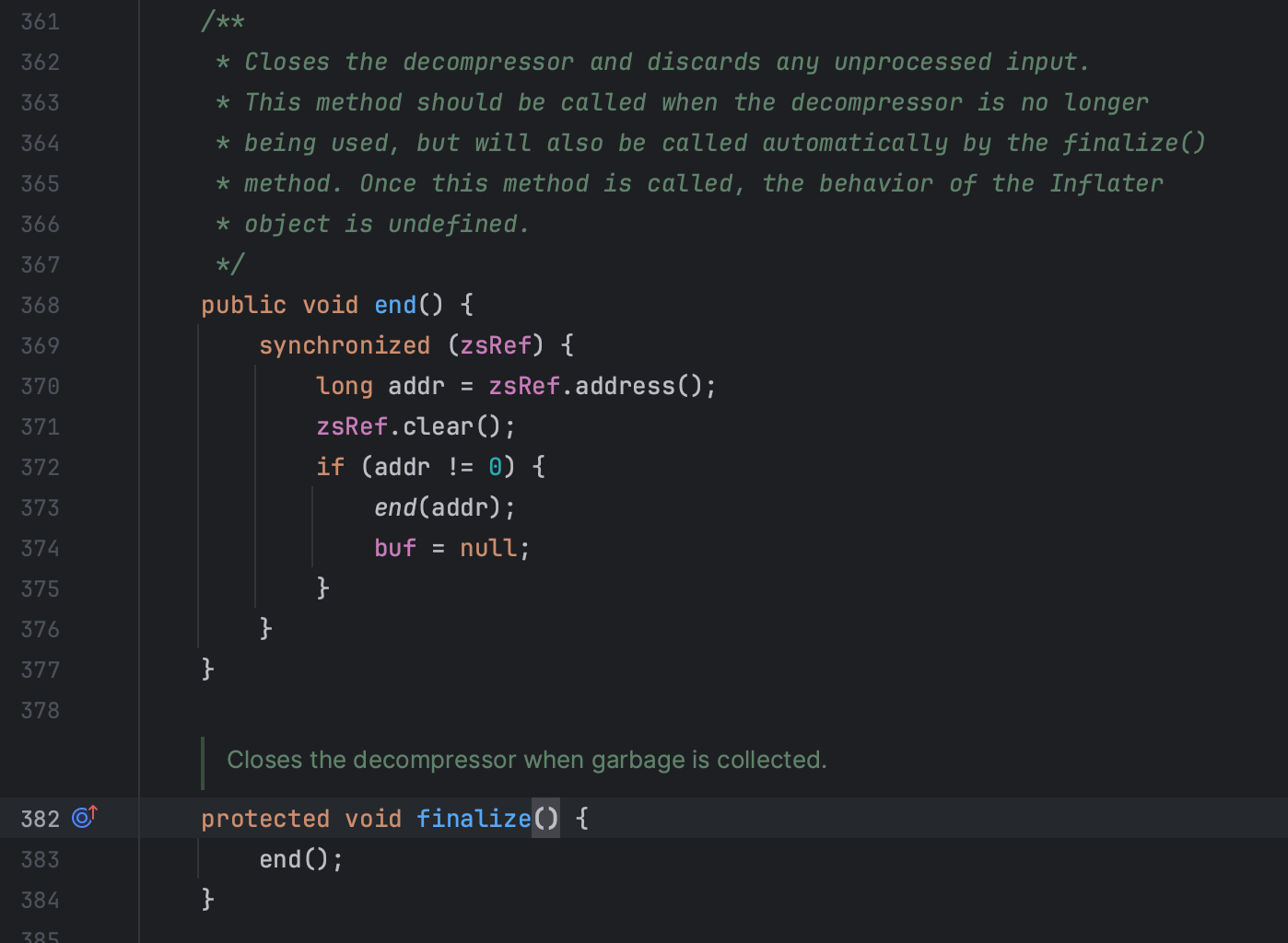
分析Inflater和InflaterInputStream
分析InflaterInputStream中的close方法,发现其在close时不一定会释放内存,而是依赖于Inflater类被回收时,调用finalize方法时释放内存。
观察Inflater在堆内存的数量
在压测前,压测后,手动gc后分别观察java.util.zip.Inflater对象的数量。
jmap -histo <pid> | grep java.util.zip.Inflater观察堆里的对象数
jcmd <pid> GC.run手动执行GC发现压测后确实比压测前多了很多java.util.zip.Inflater对象,手动gc后减少了很多,但是从top里观察内存并没有减少占用。
内存碎片分析
考虑到是内存碎片的原因,使用tcmalloc代替Linux默认的内存分配器ptmalloc。
使用tcmalloc压测后,top里的内存占用为5.8G,jcmd里的内存committed total为5.5G。 对比使用ptmalloc压测后,top里的内存占用为6.8G,jcmd里的内存committed total为5.5G。 再使用pmap观察进程内存分布,发现之前存在的大量15MB左右的内存块已经没了。推断为大概率是内存碎片导致内存释放后,内存分配器没有把内存还给操作系统。
使用jemalloc压测过程中,top里的内存占用为5.8G,和tcmalloc基本一致,不过jemalloc内存有浮动,在5.6-6G之间浮动,但大多数时间保持在5.8G。 然而jemalloc在压测完后,手动执行GC之后,内存降到5.4G,这里应该就是因为java.util.zip.Inflater被回收后释放的内存,而tcmalloc和ptmalloc在手动GC后,内存占用不会产生变化。从pmap里观察堆内存的RSS值和手动GC前一致,所以该减少不是因为堆GC的原因。所以推导在该场景下jemalloc比tcmalloc内存碎片整理更好。
结论为:jemalloc > tcmalloc >> ptmalloc。
后记
之后发现可以通过gdb调用malloc_stats来检查glibc缓存的内存大小,调用malloc_trim(0)释放缓存的内存。也可以通过tcmalloc或者jemalloc检测是否有内存泄漏。这样排查会更方便。